Continuous Quality Scoring for AI Agents
Evaluate agent quality, safety, and performance across the entire lifecycle. From golden datasets in development to automated scoring in production.
Ship with Confidence
Validate agents against curated datasets before deployment. Run experiments to compare prompts, models, and configurations — and promote only what passes.
Catch Regressions Early
Automated evaluation pipelines sample production traffic and score for quality, safety, and relevance. Drift alerts notify teams the moment quality degrades.
Improve Continuously
Create a feedback loop between production evaluations and development improvements. Track evaluation scores over time to measure progress.
Test Agents Before They Reach Users
Evaluate agents with curated datasets, stress tests, and experiments before any deployment. Catch quality issues, safety risks, and edge cases early.
- Score responses against golden datasets with automated evaluation pipelines
- Run A/B experiments comparing prompts, models, and parameter configurations
- Stress-test agents with adversarial inputs and edge cases
- Set quality gates that block deployments below your thresholds
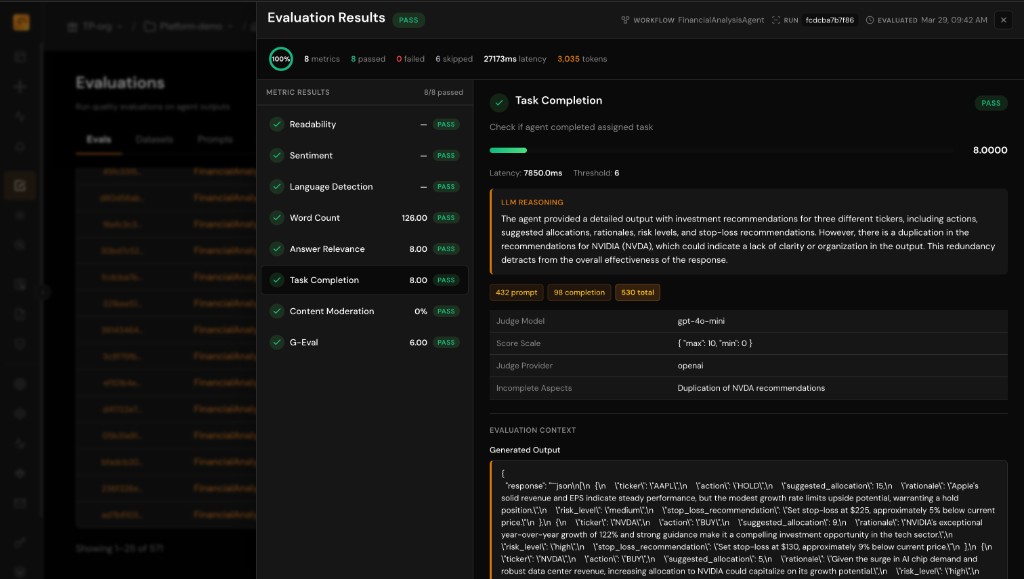
Score Every Interaction at Scale
In production, TuringPulse automatically routes sampled interactions through evaluation pipelines — scoring for quality, safety, and business relevance.
- Configure sample rates for production evaluation routing
- Use LLM-as-judge, heuristic rules, or custom ML model evaluators
- Track evaluation scores alongside traces for full context
- Set up drift alerts to detect quality regression over time
Bring Your Own Judge
Use TuringPulse's built-in evaluators or bring your own. Support for LLM-as-judge with any provider, custom heuristic rules, and ML model evaluators.
- Built-in evaluators for faithfulness, relevance, toxicity, and PII detection
- LLM-as-judge integration with OpenAI, Anthropic, Google, and custom endpoints
- Custom heuristic rules for domain-specific quality checks
- ML model evaluators for classification and regression scoring