Optimize AI Agent Costs at Scale
Track token usage, LLM costs, and resource allocation for every agent interaction. Understand where money is spent and optimize total cost of ownership.
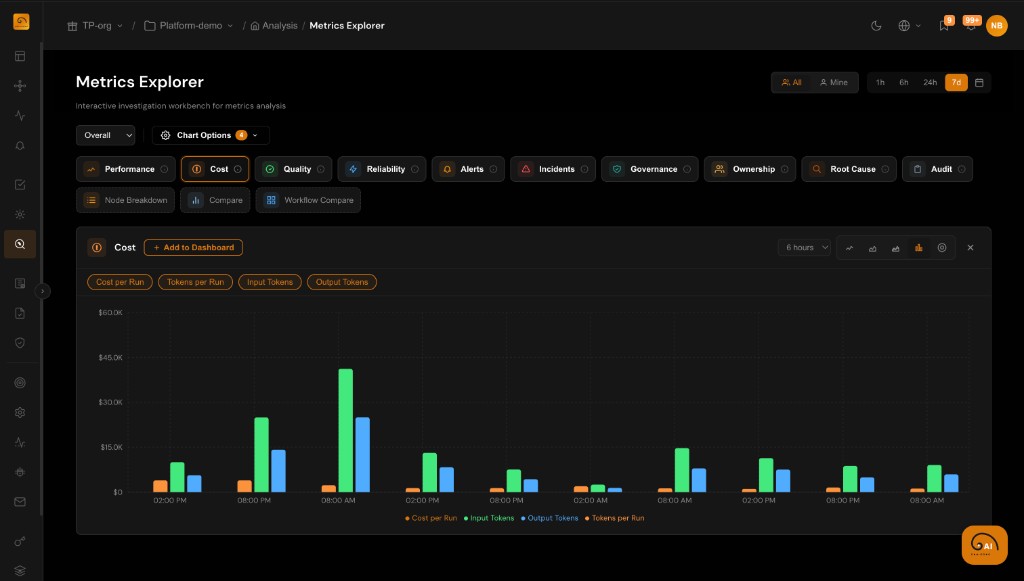
Granular Cost Visibility
See token usage and cost for every span, trace, agent, and workflow. Break down costs by model, project, and time period.
Budget Controls
Set cost thresholds and get alerted when spending exceeds budgets. Prevent runaway costs with proactive monitoring.
Optimize ROI
Combine cost metrics with quality scores to measure cost-effectiveness. Identify expensive but low-value agent paths and optimize.
Track Every Token, Every Dollar
TuringPulse records token usage at the span level for every LLM interaction — giving teams the data they need to understand and control AI costs.
- Per-span token tracking: input tokens, output tokens, and estimated cost
- Aggregate cost views by agent, workflow, project, and time period
- Cost trends and usage analytics for budget planning
- Model comparison: see cost differences between model versions and providers
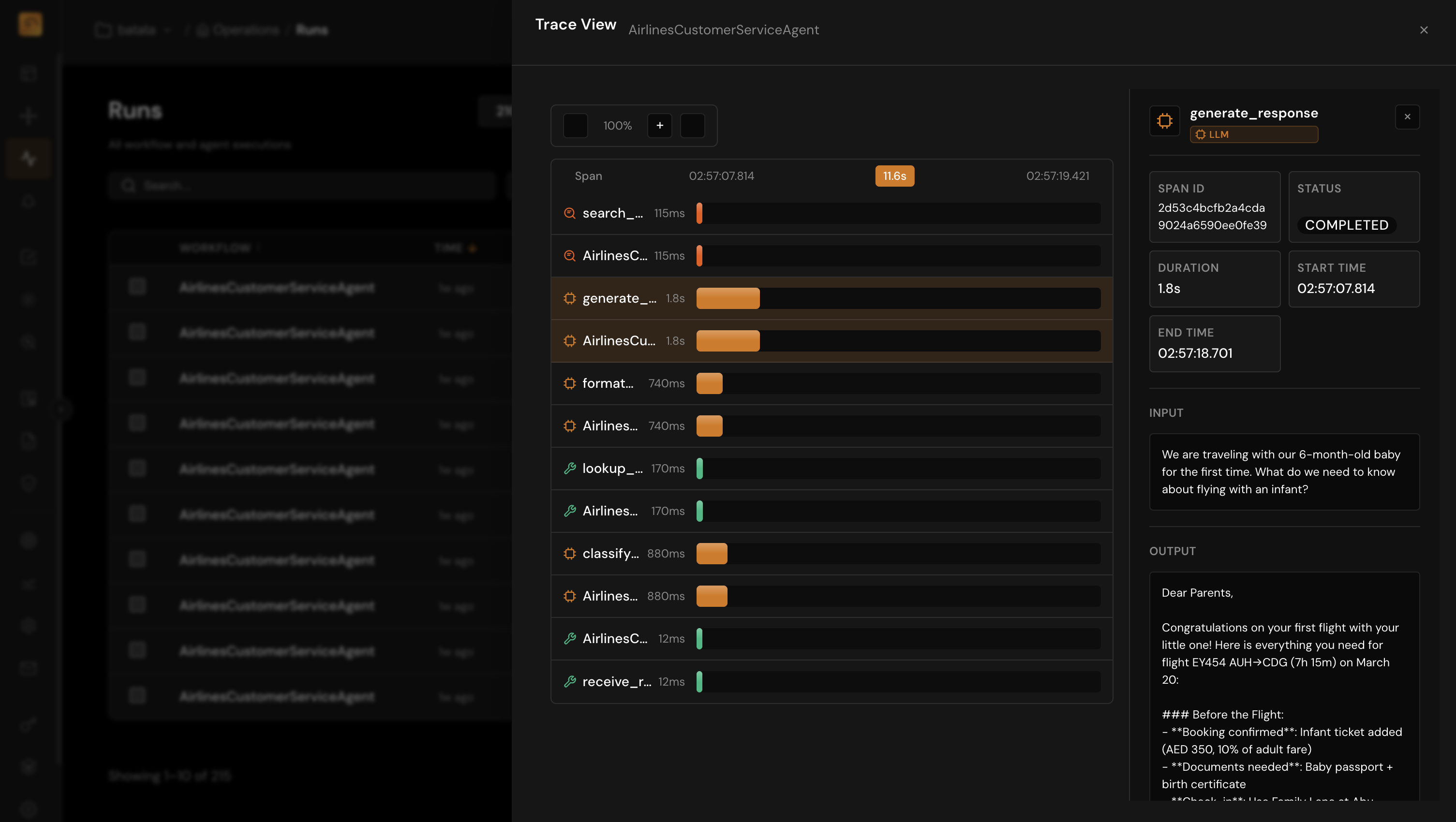
Find and Eliminate Waste
Identify expensive agent paths, redundant LLM calls, and inefficient tool usage. Optimize resource allocation to reduce costs without sacrificing quality.
- Identify high-cost, low-quality agent paths for optimization
- Detect redundant or unnecessary LLM calls in agent workflows
- Compare cost-effectiveness across different model configurations
- Track cost impact of prompt changes and agent updates