Drift & Anomaly Detection for AI Agents
Statistical monitoring, baseline comparisons, and clear anomaly signals—so silent degradation in prompts, tools, or upstream data never becomes a silent outage.
Statistical Monitoring
Track KPIs and custom metrics continuously with distribution-aware methods—not brittle static thresholds alone.
Baseline Intelligence
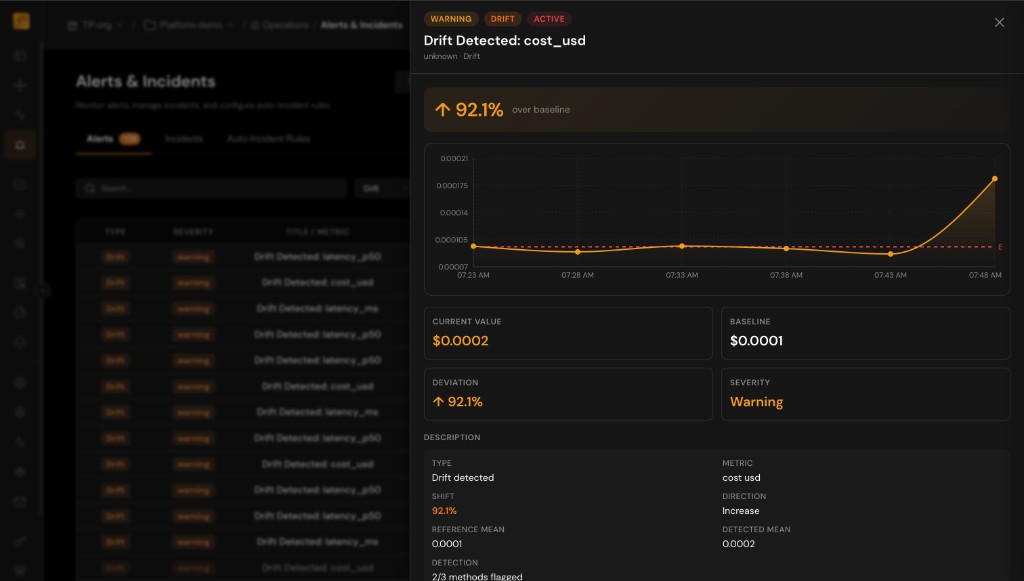
Compare traffic to historical or rolling baselines per workflow and agent. Know whether a spike is noise or a real departure from last week.
Anomaly Classification
Separate drift from one-off spikes with composite rules and severity. Route the right signal to the right team.
Drift Detection Methods You Can Explain
Pick the statistic that fits each metric—mean shift, tail risk, or relative change—and document it for auditors and engineers alike.
- Z-score alerting when values diverge from baseline mean and variance
- Percentage-change bands for cost, token volume, and business ratios
- IQR-based detection for heavy-tailed latency and duration signals
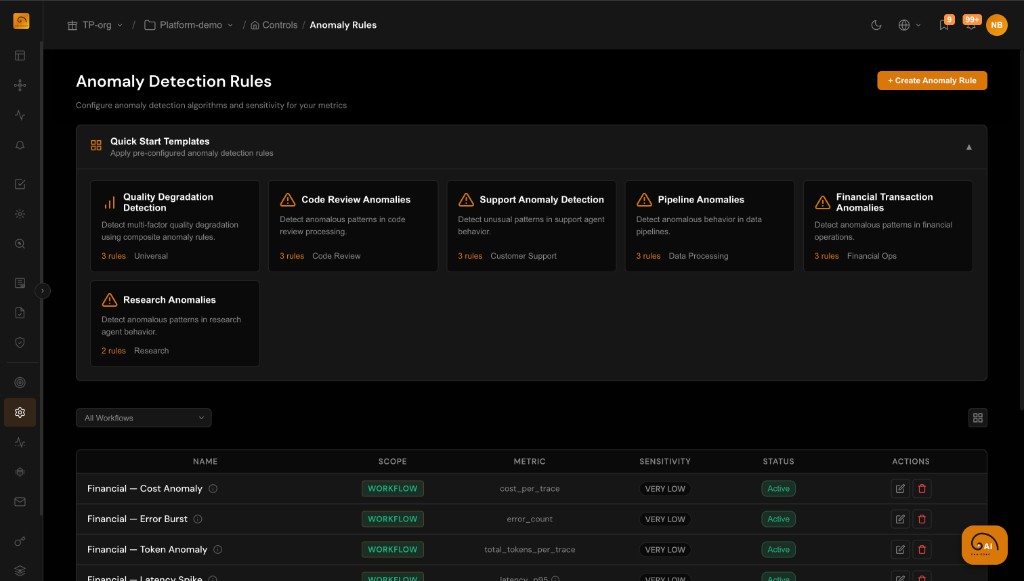
Anomaly Rules: Threshold, Pattern, and Composite
Model simple spikes, sustained shifts, and multi-signal conditions without bespoke monitoring jobs for every agent.
- Threshold rules for hard limits on errors, refusals, or latency
- Pattern rules that catch unusual tool sequences or empty outputs
- Composite conditions combining drift scores with categorical flags
Alert Routing That Respects Ownership
Drift and anomalies only help if the right people see them. Route policy-sensitive signals to compliance channels and engineering to Slack.
- Slack, Microsoft Teams, Telegram, email, and webhook destinations per rule set
- Severity and channel mapping aligned to your on-call rotation
- Context-rich payloads linking back to traces and KPI charts