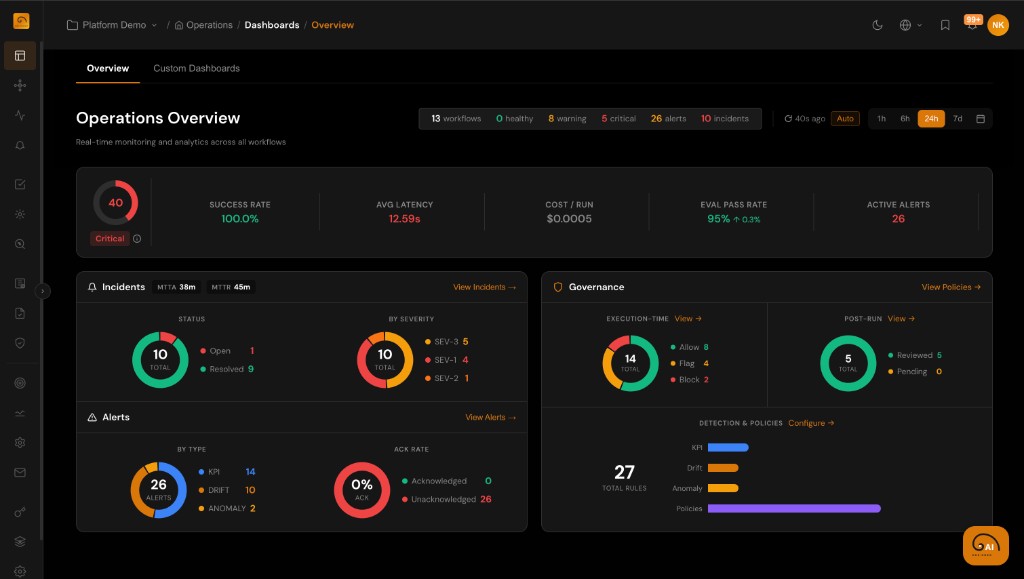
Quality Assurance for AI Agents
Automate evaluations, catch regressions across versions, and score trust for every agent run—so shipping updates to LLM-powered systems feels as rigorous as shipping code.
Automated Evaluations
Run rubrics, judges, and rules at scale on production or staging traffic. Every run can carry structured quality signals instead of manual transcript spot-checks.
Regression Detection
Compare models, prompts, and tool configs across versions. Know when a change lifts latency, cost, or error rates while quality slips.
Trust Scoring
Roll up eval outcomes and KPIs into trust indicators per workflow and version. Give stakeholders one place to answer whether the agent is still safe to run.
Evaluation Frameworks That Match Your Stack
Design evaluation programs that fit how your team ships—from strict checklists to nuanced LLM judges—without another disconnected QA tool.
- Custom rubrics with weighted criteria and explicit pass/fail gates
- LLM-as-judge flows with templated prompts and human review hooks
- Heuristic rules on span attributes, tool usage, and output patterns
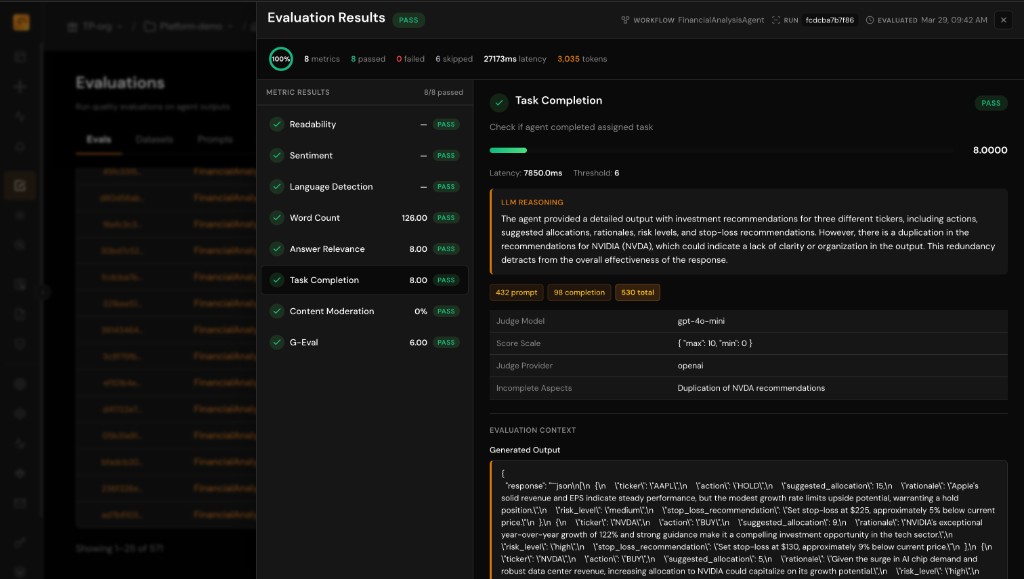
Regression Testing Across Versions and Experiments
Baseline old behavior, measure the new one, and promote only when quality, safety, and cost stay within bounds.
- Compare runs across deployments, prompts, and model versions in one view
- A/B-style analysis for staged rollouts and canary traffic
- Slice metrics by tenant, workflow, or agent to isolate regressions
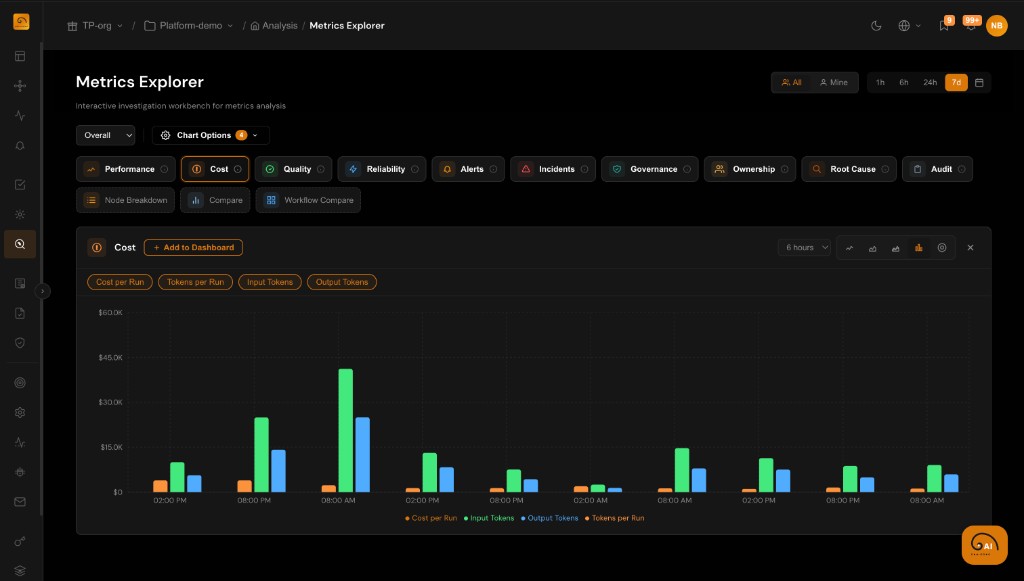
Quality Dashboards Teams Actually Use
Engineering, product, and risk stakeholders each need a different lens. Centralize scores, trends, and exceptions instead of exporting CSVs from five tools.
- Workflow- and agent-level quality summaries with time-range controls
- Drill from aggregate scores into failing runs and span-level detail
- Connect eval trends to cost and latency to trade off speed versus quality